Introduction
One of Go’s main selling points, at least for me, is its support for concurrency. Starting a go routine is almost ridiculously easy, and channels make communication between go routines a breeze.
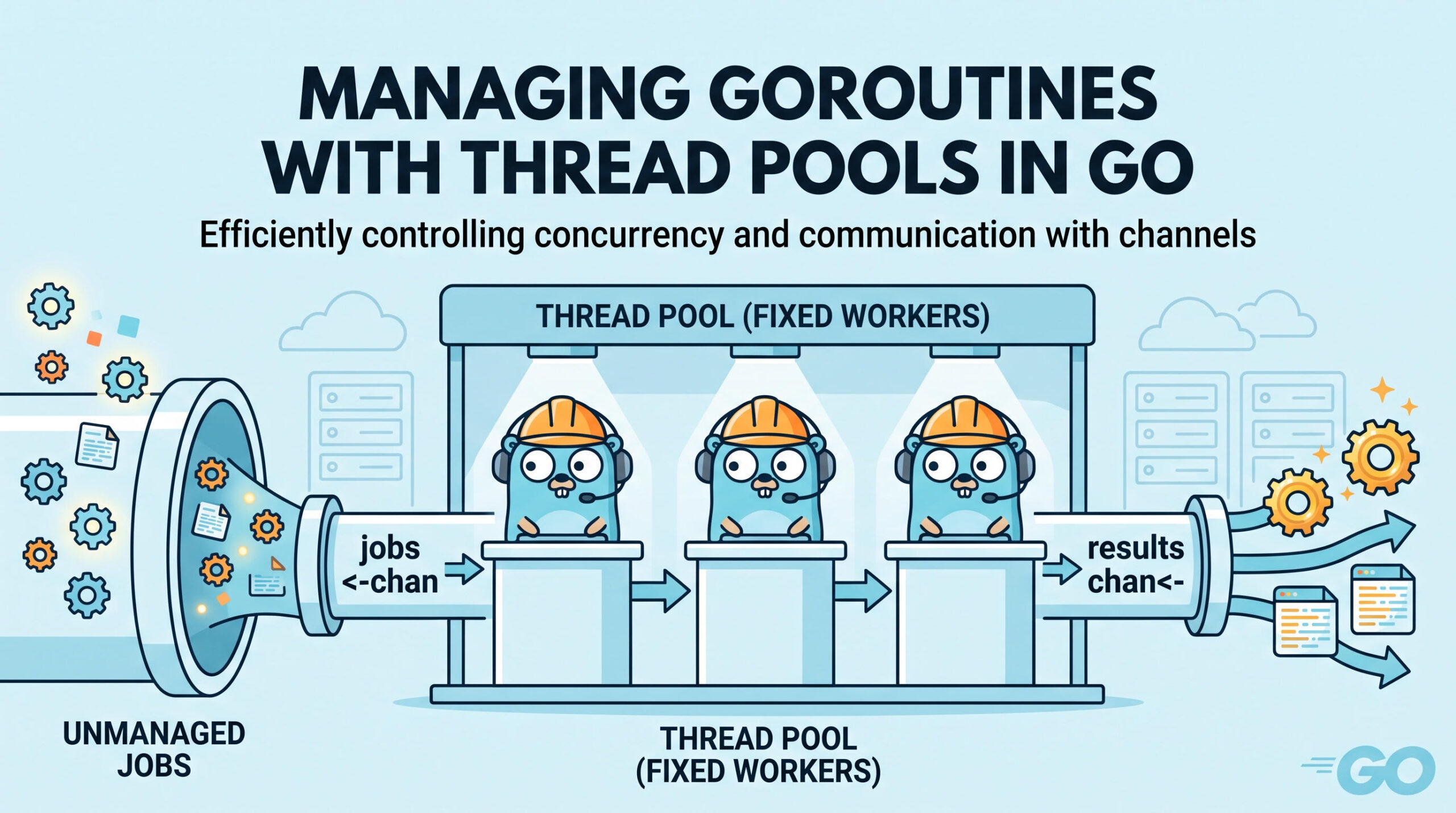
However, as the saying goes, with great power comes great responsibility: just the fact that you can easily spin up goroutines, means it can get out of control. Computers, server and laptops alike, even though they are powerful have a limited capacity.
Therefore building some sort of limitation is in order, hence the idea of a threadpool was born: a fixed number of threads are spun up, waiting for data to process and returning the results on a channel. This way we prevent overload yet we can enjoy the advantage which concurrent processing can bring.
Implementation
In this project we will define a worker function, which will be run in a go routine. This function is generic, receiving an id, an inbound channel for the jobs, an outbound channel for the results, a reference to a sync.WaitGroup and a reference to a function to process the incoming data.
We will start by defining the function type:
type ProcessFunc[T any, R any] func(T) RThis defines a generic function with one parameter of type T and a result of type R. Depending on your situation you should change this.
Next we have the worker function itself:
func worker[T any, R any](id int, jobs <-chan T, results chan<- R, wg *sync.WaitGroup, process ProcessFunc[T, R]) {
defer wg.Done()
for j := range jobs {
fmt.Printf("Worker %d started job %v\n", id, j)
time.Sleep(time.Second)
result := process(j) // Call the custom processing function
fmt.Printf("Worker %d finished job %v\n", id, j)
results <- result
}
}What is happening here?
- We first make sure the wait group is updated once the function ends, that is what the
deferis for. - Next we wait for data to be sent to the jobs channel.
- If we have received data, we process it, using the provided
processfunction - We put the result of the processing on the results channel.
Note that once the jobs channel is closed the loop ends, and the wait group will be updated. That is the way to terminate the thread pool.
The calls to Sleep are there to simulate some real work, and probably won’t be necessary in your implementation.
This all looks surprisingly simple, and it is, yet it is thread safe, so let’s try it out in the main() function. We will start with the declaration of some variables, like the number of jobs, the number of workers and the waitgroup. The latter one has to be global, otherwise we would be sending a new waitgroup to each worker go routine, rather defeating the purpose of this excercise:
const numJobs = 5
const numWorker = 3
jobs := make(chan int, numJobs)
results := make(chan int, numJobs)
var wg sync.WaitGroupNext define the custom processing function:
multiplyByTwo := func(job int) int {
return job * 2
}Start the go routines:
for w := 1; w <= numWorker; w++ {
wg.Add(1)
go worker(w, jobs, results, &wg, multiplyByTwo)
}Now we can send data to the worker go routines:
for j := 1; j <= numJobs; j++ {
jobs <- j
}We have sent all our data, so stop the workers:
close(jobs)Next we wait for the workers to finish:
go func() {
wg.Wait()
close(results)
}()Why is this in a go routine, you ask? Well, let’s look at the flow of this program:
main()is started as a go routine, and can start reading from results immediately (which will in the following code block)- This background routine patiently wait for the workers to finish.
- The workers can send to the results channel with blocking, after all, the main go routine is still consuming.
- When all workers finish, the call to
wg.Wait()unblocks, result is closed and the main’s range loop, which we will see in the next code block, exits. That way we prevent deadlocks.
Next we will read from the result until it is closed by the previous go routine:
for a := range results {
fmt.Println(a)
}That’s it. The full program looks like this:
package main
import (
"fmt"
"sync"
"time"
)
type ProcessFunc[T any, R any] func(T) R
func worker[T any, R any](id int, jobs <-chan T, results chan<- R, wg *sync.WaitGroup, process ProcessFunc[T, R]) {
defer wg.Done()
for j := range jobs {
fmt.Printf("Worker %d started job %v\n", id, j)
time.Sleep(time.Second)
result := process(j) // Call the custom processing function
fmt.Printf("Worker %d finished job %v\n", id, j)
results <- result
}
}
func main() {
const numJobs = 5
const numWorker = 3
jobs := make(chan int, numJobs)
results := make(chan int, numJobs)
var wg sync.WaitGroup
// Define your custom processing function
multiplyByTwo := func(job int) int {
return job * 2
}
for w := 1; w <= numWorker; w++ {
wg.Add(1)
go worker(w, jobs, results, &wg, multiplyByTwo)
}
for j := 1; j <= numJobs; j++ {
jobs <- j
}
close(jobs)
go func() {
wg.Wait()
close(results)
}()
for a := range results {
fmt.Println(a)
}
}
Conclusion
Go is deservedly well known for its support for concurrency. As you can see in this example, building a simple thread-safe thread pool is easy, and the code is clear. As with all concurrent code in any language, you must be aware of deadlocks, but the use of channels and waitgroups makes preventing these easy to spot and therefor easy to prevent.
If you want to have more programming news, and want to receive a free pdf about setting up a Web API with chi, pgx and goose, please subscribe to my Newsletter.



